
Breakdown of Scheduling in Erlang
There are some underlying features that make Erlang a powerful soft real-time platform. One of the features is scheduling mechanism that is well worth exploring. In this article let's explore the history of Erlang scheduler and Erlang processes' scheduling mechanism.
What is Scheduling?
Scheduling is a mechanism that assigns tasks to workers (resources) like threads in a way that maximizes efficiency and fairness while minimizing response time and latency. It's crucial in multitasking systems like operating systems and virtual machines and comes in two types:
-
Preemptive Scheduler: Switches between tasks, interrupting and resuming them later based on factors like priority, time slice or reduction without task cooperation. Ideal for real-time systems.
-
Cooperative Scheduler: Requires tasks to voluntarily release control. Not suitable for real-time systems as tasks may not return control promptly.
Real-time systems typically use Preemptive Scheduling for timely responses.
Erlang Scheduling
Erlang as a real-time platform for multitasking uses Preemptive Scheduling. The responsibility of an Erlang scheduler is selecting a process and
executing based on priority, time slice or reduction bases. Erlang processes are scheduled on a reduction count basis. One reduction is roughly
equivalent to a function call. A process is allowed to run until it pauses to wait for input (a message from some other process) or until it has
executed 1000 reductions. However Erlang/OTP R12B had a support of maximum 2000 reductions.
Tasks scheduling in Erlang has decades long history. It has been evolving over the time. These changes were affected by the changes in SMP (Symmetric Multi-Processing) feature of Erlang.
Process Queue:
+---------+ +---------+ +---------+
| P1 | <-- | P2 | <-- | P3 |
+---------+ +---------+ +---------+
...
+---------+ +---------+ +---------+
| P(N-2)| <-- | P(N-1) | <-- | P(N) |
+---------+ +---------+ +---------+
P1 Execution: R1, R2, ..., R1000 (Or waiting for message)
Updated Queue (after P1's execution):
+---------+ +---------+ +---------+
| P2 | <-- | P3 | <-- | P4 |
+---------+ +---------+ +---------+
...
+---------+ +---------+ +---------+
| P(N-1) | <-- | P(N) | <-- | P1 |
+---------+ +---------+ +---------+
P2 Execution: R1, R2, ..., R1000 (Or waiting for message)
Updated Queue (after P2's execution):
+---------+ +---------+ +---------+
| P3 | <-- | P4 | <-- | P5 |
+---------+ +---------+ +---------+
...
+---------+ +---------+ +---------+
| P(N) | <-- | P2 | <-- | P2 |
+---------+ +---------+ +---------+
There are functions to slightly optimize the scheduling of a process (yield(), bump_reductions(N)), but they are only meant for very restricted use, and
may be removed if the scheduler changes.
A process waiting for a message will be re-scheduled as soon as there is something new in the message queue, or as soon as the receive timer (receive ... after Time -> ... end) expires. It will then be put last in the appropriate queue.
Erlang Scheduler Queues
Erlang has 4 scheduler queues (priorities):
- max
- high
- normal
- low
Let's take a look at max and high first. Both max and high are strict. This means that the scheduler will first look at the max queue and run processes there until the
queue is empty; then it will do the same for the high queue.
Process Queue (Max and High):
+---------+ +---------+ +---------+
| P1 | <-- | P2 | <-- | P3 |
+---------+ +---------+ +---------+
...
+---------+ +---------+ +---------+
| P(N-2)| <-- | P(N-1) | <-- | P(N) |
+---------+ +---------+ +---------+
Execution Sequence (Max and High):
P1 <-- P2 <-- P3 <-- ... <-- P(N-1) <-- P(N)
After Max Queue Execution:
[Processes in High Queue]
Execution Sequence (High):
P1 <-- P2 <-- P3 <-- ... <-- P(N-1) <-- P(N)
After High Queue Execution:
[Processes in Normal Queue]
normal and low are fair priorities. Assuming no processes at levels max and high, the scheduler will run normal processes until the queue is empty,
or until it has executed a total of 8000 reductions (8*Max_Process_Reds); then it will execute one low priority process, if there is one ready to run.
Process Queue (Normal and Low):
+---------+ +---------+ +---------+
| P1 | <-- | P2 | <-- | P3 |
+---------+ +---------+ +---------+
...
+---------+ +---------+ +---------+
| P(N-2)| <-- | P(N-1) | <-- | P(N) |
+---------+ +---------+ +---------+
Execution Sequence (Normal and Low):
P1 <-- P2 <-- P3 <-- ... <-- P(N-1) <-- P(N)
After Normal Queue Execution:
[Processes in Low Queue]
Execution Sequence (Low):
P1 <-- P2 <-- P3 <-- ... <-- P(N-1) <-- P(N)
The relationship between normal and low introduces a risk of priority inversion. If you have hundreds
of (active) normal processes, and only a few low, the low processes will actually get higher priority than the normal processes.
The priority can be specified inside a process by calling erlang:process_flag/2 function as:
PID = spawn(fun() ->
process_flag(priority, high),
%% ...
end).
Note: The default priority level is normal and the max is reserved for internal use in Erlang runtime and should not be used by others.
One important thing to note about the scheduling is that from the programmer's perspective, the following three things are invariant:
- Scheduling is preemptive.
- A process is suspended if it enters a receive statement, and there is no matching message in the message queue.
- If a receive timer expires, the process is rescheduled.
The Erlang Processor, for example, will most likely schedule based on CPU cycles (essentially a time-based scheduler). It may also have multiple thread pools, allowing it to context switch within one clock cycle to another process if the active process has to e.g. wait for memory.
In a runtime environment that supports it, it should be possible to also have erlang processes at interrupt priority (meaning that they will be allowed to run
as soon as there is something for them to do -- not having to wait until a normal priority process finishes its timeslice.)
Scheduling Before R11B
Before R11B, the Erlang VM doesn't support SMP, so that just 1 scheduler which run in the
main process thread. The scheduler had to pick runnable Erlang processes and IO-jobs from the runqueue and and execute them.
since there was only one thread accessing them.

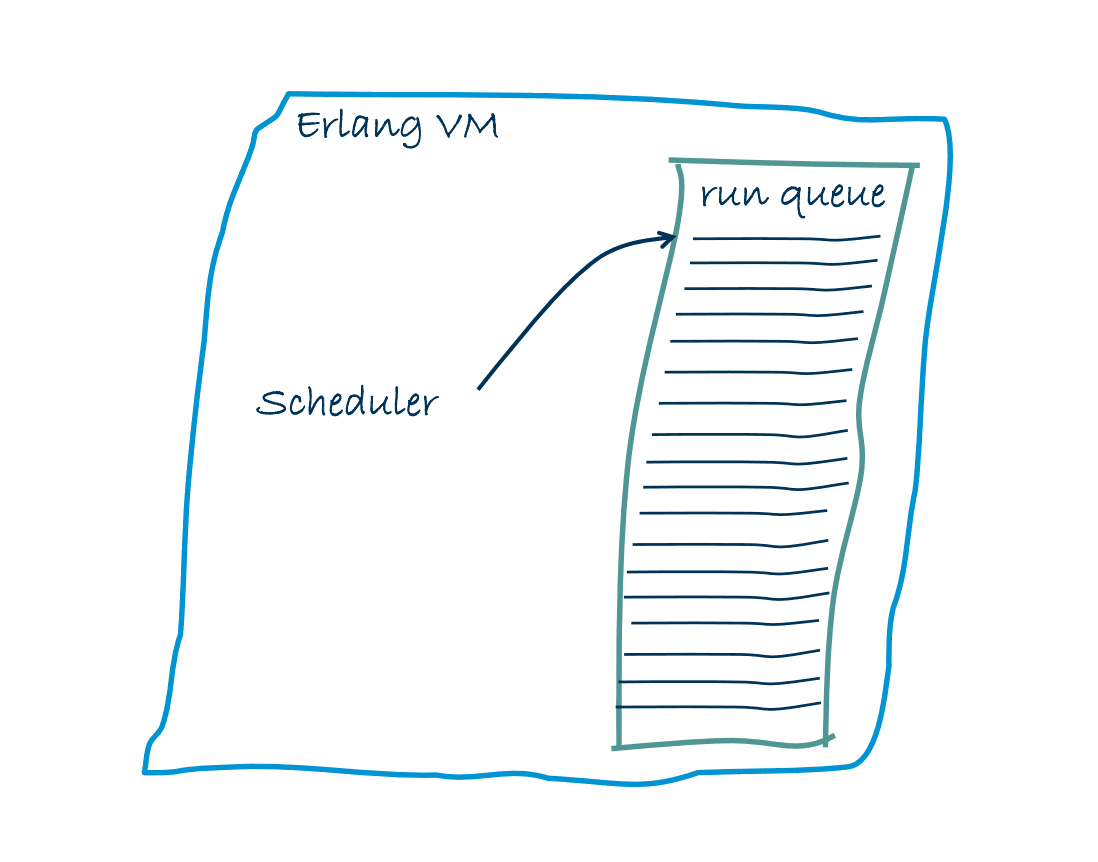
In this case, there was no need to lock data structures because application could'nt take advantage of parallelism.
Scheduling in R11B and R12B
Later on, SMP support was added to Erlang VM (in R11B & R12B) so that it could have support for 1 to 1024 schedulers, where each scheduler run in 1 OS process's thread. However schedulers still had to pick runnable Erlang processes and IO-Jobs from one common runqueue.

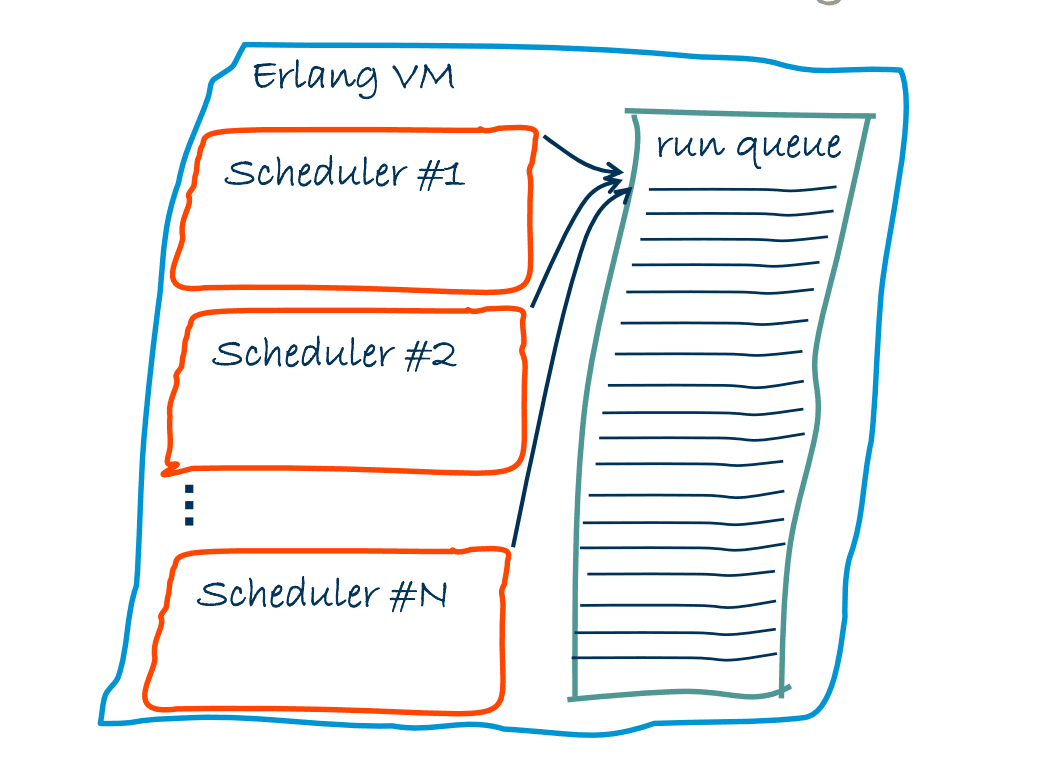
SMP VM all shared data structures were protected with locks, the runqueue was one example of a shared data structure protected with locks in parallelism mode. Although locks protected shared data strucuture but at the cost of performance. Later on as per strategy: "First make it work, then measure, then optimize", performance improvements were made in multi-core processsors system was phenomenal.
This version also brought some known bottlenecks, were as follows:
- The common runqueue was a bottleneck when CPU or CPU cores increases (increase of schedulers).
- Increasing the involved lock of ETS tables which also affects Mnesia.
- Increasing the lock conflicts when many processes are sending messages to the same process, performance penalty
- Process waiting to get a lock can block its scheduler.
To address these bottlenecks, separate runqueue per scheduler, was introduced in the laster version of the Erlang VM.
Scheduling after R13B
In the next versions, Erlang VM introduced separate runqueue per scheduler, which drastically decreased number of lock confilicts occured in the systems with many CPUs, or CPU cores, in other words, number of schedulers. This also broght big performance improvements and increased the system ability to manage Erlang processes and their execution in more efficient way.
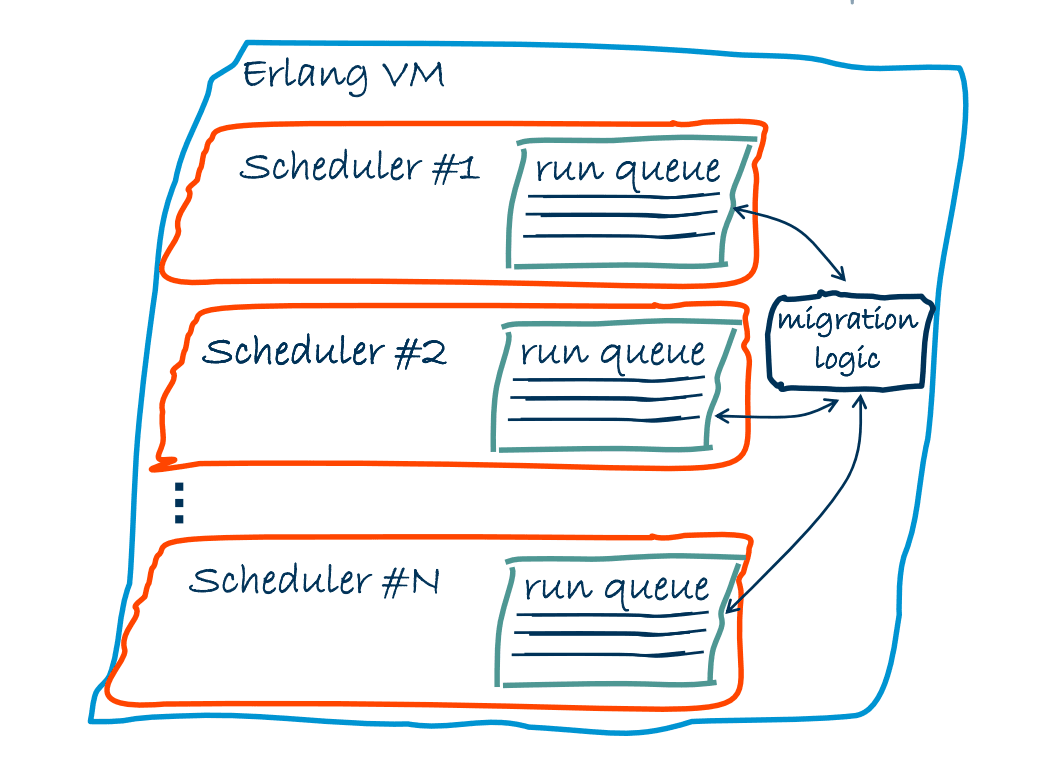
Although introducing separate runqueue per scheduler decreased lock conflicts situation, however raises some new concerns:
- How fair is the process of dividing tasks among run queues?
- What if one scheduler gets overloaded with tasks while others are idle?
- Based on what order a scheduler can steal tasks from an overloaded scheduler?
- What if we started many schedulers but there all so few tasks to do?
These concerns led the Erlang VM team to introduce a new concept for making scheduling efficient and reasonably fair, the Migration Logic. Migration logic helps to control and balance runqueues based on collected statistics from the system.
Summary
To summerize this: while implementing preemptive scheduling can be complex, in Erlang, developers don't need to handle it themselves because it's built into the virtual machine. The slight extra processing overhead for tasks like tracking, balancing, selecting, executing, migrating, and preempting processes is acceptable when scaling across processing resources fairly and ensuring timely responses in real-time systems. Notably, Erlang's fully preemptive scheduling sets it apart from many other high-level platforms, languages, or libraries.
Reference Links: